
Chess is a complex problem from a programming perspective hence creating a database for chess is challenging. In this blog post series, I will discuss the Requirements, design, and implementation of a chess database that we used to create Scriptchess. But before jumping into design details, let me tell you, why I decided to write a chess database from scratch?
Part 1: How to write a cost-effective database for chess from scratch
Part 2: Compressing a PGN File
Part 3: Compressing FEN with Moves and Game Details
Why I decided to write a chess database from scratch?
Creating a database is a very complex task as you will have to take care of many things like concurrency, performance, accuracy, availability, etc. I had the exact requirement but I was not able to achieve all of these in a cost-effective way using standard databases available in the market. The kind of computing required to handle data of millions of games and then querying them was taking a very long time and in order to minimize the time I had to upgrade the hardware which increased the cost heavily. I was left with no choice but to write a database from scratch.
Requirements of a chess database?
Let's first discuss the requirements of a chess database.
- You Should be able to fetch, store, update, and delete a chess game using PGN
- You Should be able to fetch games of a player
- You should be able to fetch Games played between two given players
- You should be able to fetch Moves played in a given position (using FEN)
- You should be able to fetch games where a given position reached
- You should be able to take a backup of the database
- You should be able to Restore the database
I had a good reason to not use requirements 2 and 3 from my implementation, because of Cost. The solution I will be discussing will definitely implement all of the features mentioned above but will pile up a lot of objects on file which might eventually crash the JVM or overshoot the memory requirement. If you have a higher RAM then you may choose this implementation. I personally used MongoDB for these requirements. Let's discuss the limitations that I had to consider while writing this database.
Limitations that I considered
Below are the limitations that I had to consider:
- Must not add another penny to the cost until the data exceeds my physical (secondary memory or hard drive) drive.
- Must work efficiently with 1 GB of RAM
- Should serve responses to every query within 100ms on an average
- The initial size of the hard drive will be approximately 20 GB.
The above limitations are taken from AWS EC2's T2 Micro instance. Please be aware that this will not cost you a penny for the first year.
Design of the Chess database
Storing the game Files
Our Database is file system based. It stores games and positions in files. You can also store game metadata in a separate file for query purposes, Just in case you do not want to use other databases for query purposes.
Below are the details of the files that contain the games:
- One game will be stored in exactly one file
- The path of the file will be identified by the id of the game.
- Since one directory can store a limited number of games, hence we will have to create a hierarchy of directories to store games.
- The hierarchy shouldn't be deep as each folder takes up to 4kb which is much more than the size of a PGN file, hence we need to minimize the number of directories
- The content of the PGN file will be compressed to further minimize the size of the file. (Will be discussed in separate post)
Since the path of the file is decided by the ID of the game hence special attention needs to be given to the game ID generation. The ID should be generated in such a way that it results in less and less number of directories.
We create the ID of the game using the time of creation. Below is the code for the Game Id generation
Click here for Github gist
The above method generated will generate an ID as “7E7-18-09-C216E”
- Each ID will be separated by 3 “-” (hyphens)
- The first part will be the Year in which the game is created
- The next part will be the date on which the game was created
- The Third part will be the hour
- The rest part will be batched together with Minutes seconds and milliseconds
path of the game with this id will be <Directory of all games>/7E7/18/09/C216E.game (the game will be an extension of the file)
In this way all the games created in entire years will be in a single directory further all games created within a particular hour will be inside one directory. If you choose to create games in bulk, most probably you will end up having thousands of games inside a single directory. the overhead will be 3 directories which means 12kb (4Kb for each directory)
Storing the Positions of the game
Storing the position comes with additional challenges. First of all, let's understand the requirements of storing a position, which means what we will get from a position? Here are the things that we need to store and fetch from a given position:
- Number of games this position is reached
- What are the different moves that were played in this position along with the number of times these moves were played, and the corresponding results
- What are the latest 1000 games where this position is reached
For example, consider the following position:

In the above-given position, we get the below information from the current scriptchess database
Game IDS: 1211BBE7, 139111155 ….
Moves:
| Move | White WIns | Black wins | Draws | Total Number |
| Be4 | 2 | 1 | 1 | 4 |
| Bg4 | 9 | 4 | 9 | 22 |
| Nc8 | 6 | 12 | 12 | 30 |
| Ng6 | 0 | 1 | 2 | 3 |
| a6 | 0 | 2 | 0 | 2 |
| h6 | 0 | 0 | 1 | 1 |
Now in order to save this information along with FEN we need to define a strategy keeping in mind that we will have to save these in files and also that the number of positions that we will be saving will be huge (in hundreds of million)
Since the number is huge, we can't use a similar strategy as of games, where we were saving one game in one file, since we will have to create lots of files in lots of directories. And we can't save them all in a single file as well, otherwise, the writing and reading both will become expensive operations.
We can use a bucket system to save the FENs. Just the way Hashmap works, we will create a bucket number from any given FEN in such a way that the number of buckets will not exceed a pre-decided number. These bucket numbers will be used as file names where FENs and related information will be written.
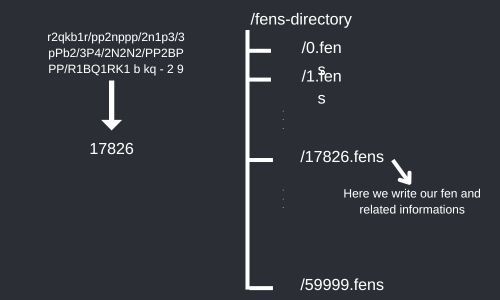
So the first thing that we will need is an algorithm that will calculate the bucket number for any given FEN. here's one.
Click here for Github gist
The above algorithm generates buckets considering there will be 1 Billion positions to save and each bucket should ideally contain 20,000 fens, resulting in 50,000 buckets.
Hence according to the above algorithm, fens will be stored in 50,000 files and each file will supposedly have a max number of 20,000 positions. But this is only an ideal condition, a file may contain more than 20,00 positions but the max number of files will be 50,000. So whenever you want to search a FEN, using this bucket you'll only have to search through a very small subset of the FENs. Now let's look at the algorithm to save and read a FEN.
Click here for Github gist
With the above sequence of instructions, you will be able to write any given FEN into the correct bucket. Reading a fen will be fairly simple, in fact, it is used already in the writing process, in order to find if the fen is already written. Here's code for reading a FEN
Click here for Github gist
The above methods show how we can store and fetch a given FEN with all required information efficiently. I have tested this over a REST service with over 10k requests within a 10sec span and the avg response time was around 90 ms. I was serving the requests from a T2 micro EC2 instance.
Everything worked as per expectation bbut the limitation of space was still something that butI had to consiuder. Hence I came up with an algorithm to compress FEN and that saved me 30% of the memory.
Next two article would be around compression of PGN and FEN.
If you want, you can explore the complete codebase of scriptchess's chess-db






Leave a Comment: